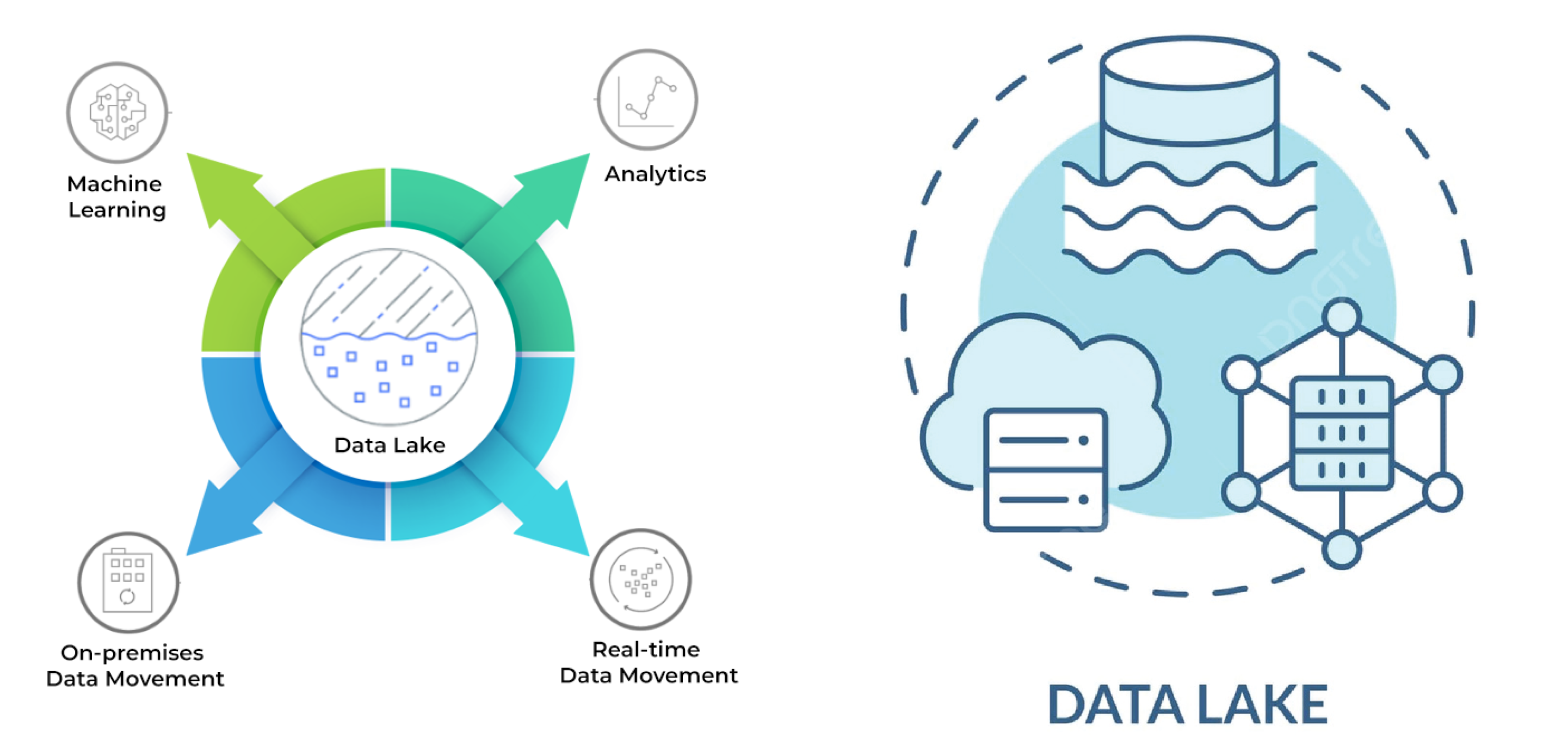
Defining Custom Data lake House for Data storage, Analytics and AI Development
Merlin S – Director – Software & Data Science
Scalability and Flexibility for Analytics and Machine Learning:
Scalability is crucial when handling large volumes of engineering data, which often grows exponentially over time. Data lake houses are designed to scale horizontally, leveraging cloud storage solutions to accommodate increasing data volumes without compromising performance. This scalability is essential for conducting complex analytics and developing machine-learning models that require access to both raw and aggregated data in real-time. Additionally, the flexibility of data lake house architectures supports diverse data processing requirements, enabling engineers to use custom scripts and powerful data processing libraries for advanced analytics tasks.
Support for ACID Properties and Data Integrity:
In engineering environments where data integrity and transactional consistency are paramount, the ACID (Atomicity, Consistency, Isolation, Durability) properties play a crucial role.Unlike many NoSQL databases that may sacrifice ACID guarantees for scalability, data lake houses can maintain these properties for operational and administrative data. This capability ensures reliable data storage and retrieval, critical for engineering workflows that involve sensitive information. By adhering to ACID principles, data lake houses provide a robust foundation for maintaining data integrity throughout the data lifecycle.
In summary, leveraging a data lake house offers significant advantages in managing complex engineering data, including unified data management, scalability for analytics and machine learning, and robust support for ACID properties. These benefits make data lake houses a preferred choice for modern engineering teams aiming to harness the full potential of their data assets effectively.







